The Playground project is automatically created when you sign up to the AI & Analytics Engine, containing a gallery of data and ML apps to experiment with.
A number of datasets, data-wrangling recipes and apps are automatically created for you to explore and understand the capabilities and values the Engine can bring to your business.
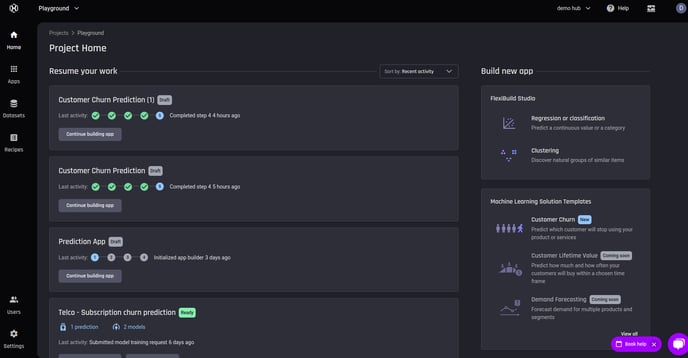 The Playground project homepage
The Playground project homepage
To access this project, go to the project listing page using the PI.EXCHANGE logo from anywhere on the Engine, and locate the Playground project by name:
The following apps are available in the Playground project:
|
App name |
Type |
Description |
|---|---|---|
|
Banking - Transactional churn prediction |
ML Solution Template - Customer churn (transactional) |
Predicting customers’ spending behaviour will decline in volume or total value, in a future time frame |
|
Telco - Subscription churn prediction |
ML Solution Template - Customer churn (subscription) |
Predicting whether customers will be cancelling their telco service subscription in the defined time frames |
|
Titanic - Survival prediction |
FlexiBuild - Classification (binary) |
Using a use case dataset popular with those learning ML for the first time, the app illustrates how the Engine’s data-wrangling recipe can be easily used to create interesting features using domain knowledge |
|
Healthcare - Heart disease prediction |
FlexiBuild - Classification (binary) |
Predicting whether a patient will have a cardiovascular condition |
|
Real estate - Sale price prediction |
FlexiBuild - Regression |
Predicting the sale price of a house given its characteristics |
|
Insurance - Vehicle policy owner segmentation |
FlexiBuild - Clustering |
Segmenting vehicle insurance policy customers based on their policy usage and their interaction with the insurance provider |
|
Retail - Customer segmentation |
FlexiBuild - Clustering |
Segmenting retail business customers based on the frequency, value, and type of purchases they make |
|
Banking - Loan default prediction |
FlexiBuild - Classification (binary) |
Predicting whether a customer seeking a loan will be on track to repay the loan after after a set time, if granted Includes a data preparation pipeline that illustrates how one can perform fairly complex feature engineering from multiple time-stamped datasets of events |
On the summary page of every app, you can inspect and explore the following:
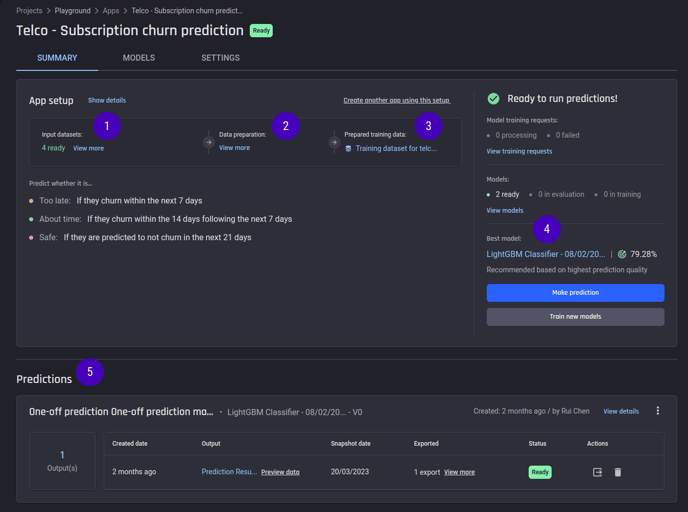
-
Input datasets
-
Data-preparation pipeline used to engineer features from input datasets
-
Prepared training dataset
-
Insights:
-
Model performance, feature importance scores, prediction explanation, and what-if tool, for regression and classification apps
-
Clustering analysis results, in case of the clustering app
-
-
Predictions, in case of regression and classification apps
You can make new predictions with new data, and deploy the models to generate an endpoint that can be accessed via API.
You can also explore the preview and analysis pages for every dataset by clicking datasets on the left hand side of the Engine
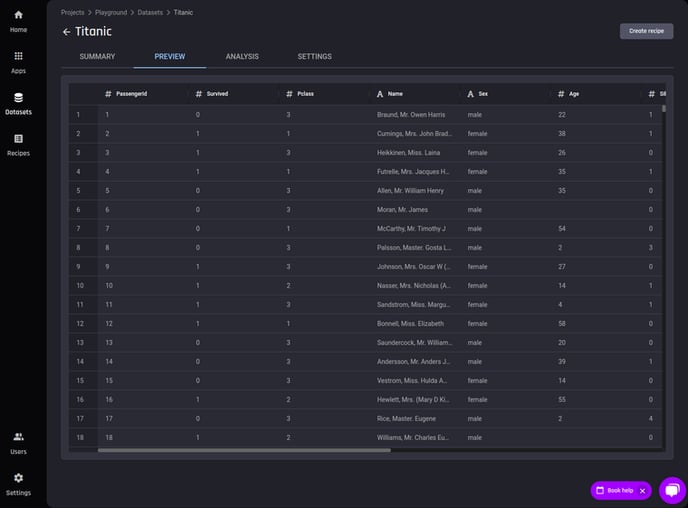 Dataset preview
Dataset preview
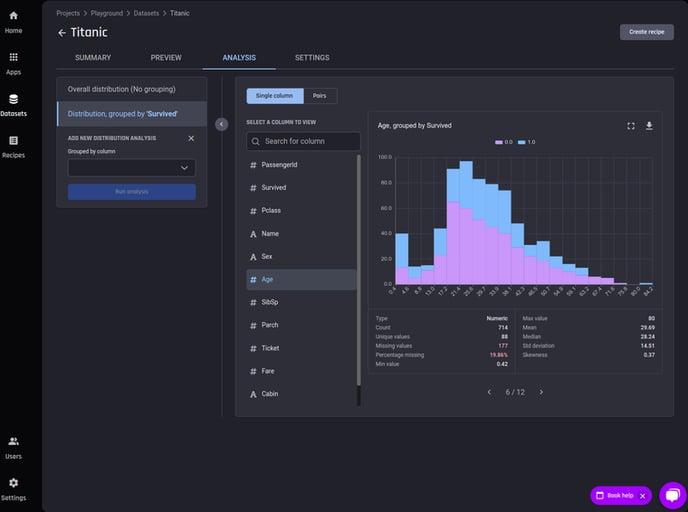 Dataset analysis
Dataset analysis