Overfitting is when a model is trained to work too well on the given dataset that it may not be good at making predictions on new and unseen data.
NOTE: This specifically applies to classification & regression problem types
In machine learning, the data used for model training is just a sample from a larger population. In practice, most datasets contain small variations in the target column that deviate from the underlying patterns that the model aims to learn. This causes a serious problem known as overfitting. Overfitting is when a model is trained to work too well on the given dataset that it tends to be poor at making predictions on new and unseen data. This is because the model captures the irrelevant variations rather than the important patterns in the training data and fails to generalize well on new data.
A real-world analogy
Let us consider the case of a student learning for an exam as an analogy:
Overfitting happens when the student only memorizes the answers to the past exam questions instead of learning the principles and concepts to answer similar question types. In this case, when the student is tested on new questions that they didn’t memorize, they cannot answer them and performs poorly.
Optimal fitting happens when the student learns the principles and concepts as they learn the answers to the past exam questions. When they take the test and see the questions that they haven’t seen during their learning, they can still answer them with their conceptual understanding.
Underfitting happens when the student does not study the past exam questions sufficiently to understand the principles and concepts. As a result, when they take the test and see questions about the concepts that they did not learn, the student performs poorly.
Overfitting in Machine Learning
In Machine Learning, overfitting can be caused by situations where a model trains for too long or considers too many feature columns. At the other extreme, if the process of model training stops too early or too many important features are removed, the opposite issue, underfitting, can happen. In this case, the model performs poorly at both training and new data.
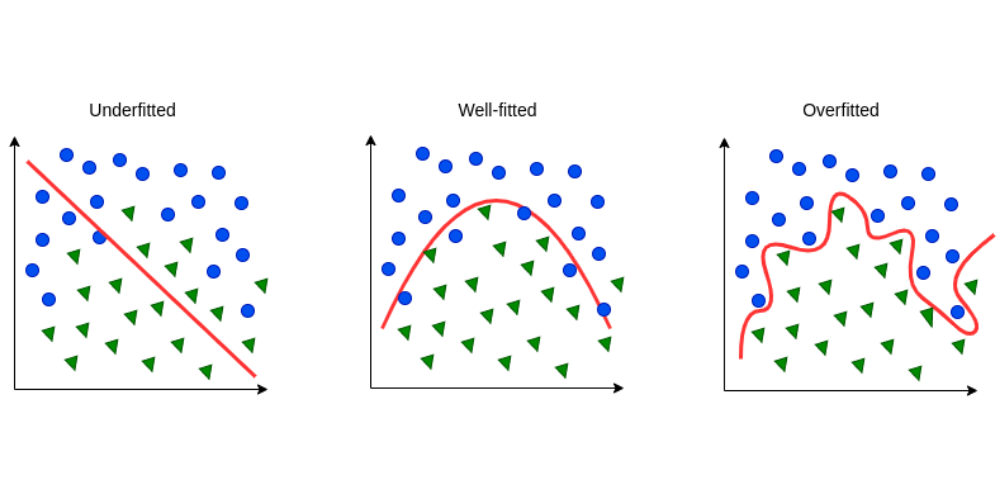
Consider the illustration below. In this case, a model tries to distinguish the blue circles from the green triangles. The red line is the boundary separating the two shapes that the model learns from the training portion.
-
In the left figure, the model is under-fitted: The boundary is a simple straight line and the model could not effectively separate a number of the green triangles and blue circles
-
In the middle figure, the model is well-fitted: The boundary is sophisticated enough to only mistake a small number of shapes that are too close to the boundary
-
In the right figure, the model is over-fitted: The boundary is too sophisticated that it only does well in the training portion. If we apply this boundary to new input data that the model is not trained with, the model might not distinguish between the two shapes well
How the AI & Analytics Engine protects users from overfitting models
The AI & Analytics Engine guards our users against the risk of overfitting their models by automatically applying a standard set of practices employed by Data Science professionals, which include:
-
Cross-validation (or a single train-validation split if the data is large) with hyperparameter tuning. This is included during the model-training process on the Engine.
-
Cross-validation enables us to evaluate the resulting model’s performance on new data under different hyperparameter configurations, using only the train data.
-
-
Automated feature selection reduces the number of features by keeping only the important features in the training data. In the Engine, useful features are automatically selected in a recommended Feature Set.
In addition to the above, users of the AI & Analytics Engine have the option to update models by training with more data via the continuous learning feature. This can help models in learning the relationship between features and the target variable more reliably. As more data is fitted, the model is less likely to be overfitted.
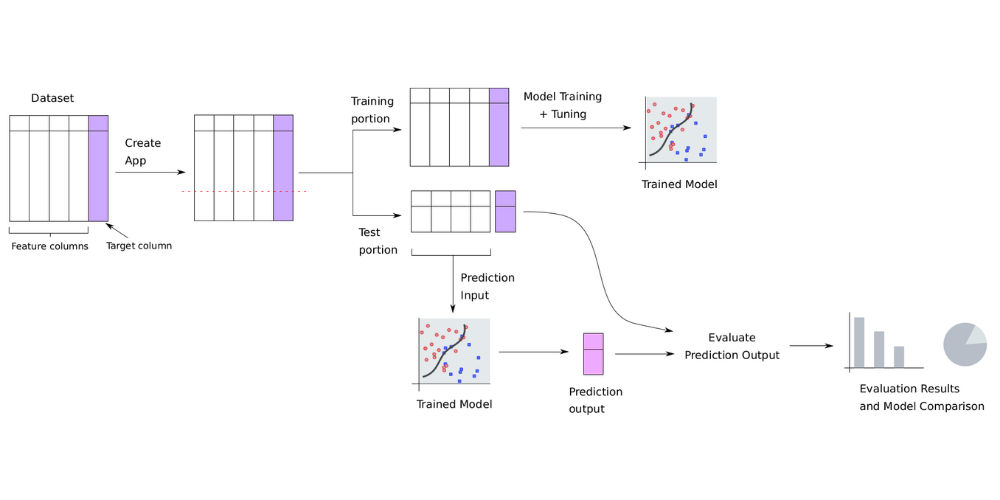
Finally, on the Engine, models are automatically evaluated based on the test (hold-out / out-of-sample) portion of the dataset, which it was not exposed to during training. This means that a model with good performance on a test portion is highly reliable and less likely to be overfitted.