A machine-learning-ready dataset is one that can be easily analyzed while allowing for feature interpretability. To transform raw data into this format, you’ll need to tailor a data-preparation pipeline based on your domain knowledge.
Though a machine-learning-ready (ML-ready) dataset is defined in various ways by the ML community, on the AI & Analytics Engine, the term specifically means a tabular dataset that describes your specific goal with examples, depending on whether it is a classification and regression or clustering use case:
Classification and regression
The dataset represents a set of training examples for the model you intend to build. Specifically, each row in isolation must be a training example, consisting of inputs stored in separate columns (called the “feature” columns) that you intend to feed your model and the output stored in its own column (called the “target” column) you expect from it for the specific instance.
Clustering
The dataset represents a set of entities or items within which you want to find naturally occurring groups of closely similar items. Each row in isolation must describe one of the candidate entities in its entirety. The attributes of each entity by which you want to define similarity must be stored in separate columns. Note that any ML-ready classification or regression dataset can be used for clustering if the target column is ignored.
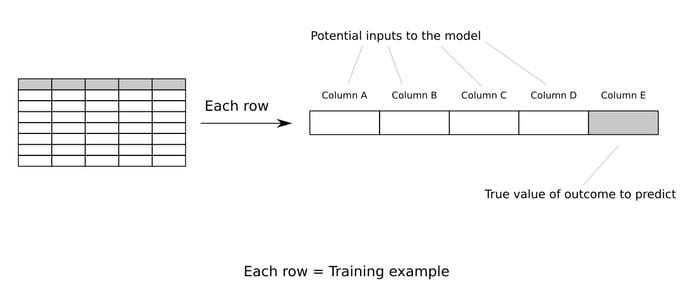
ML-ready dataset concept illustrated for classification and regression. For clustering, the target column is not required.
Dataset Example:
For example, let’s say you have a dataset containing several months' worth of transactions from a group of customers, where each row corresponds to a single transaction. You want to use this dataset to predict whether a customer will have transactions exceeding $5000 total in the following month.
Note that:
-
The data corresponding to each customer is spread out over several rows in the transaction dataset.
-
At the time of prediction, an aggregated history of transactions must be submitted to the model, and the features of an individual customer (eg. the average spend on different days of the week, the average spend on different types of items, etc.) must be computed and used to make a prediction.
-
The target column needs to be created as the result of an aggregation.
As such in its original form, the transactions dataset is not ML-ready.
The ML-ready dataset for this problem would have the following characteristics:
-
Each row in it contains information about one unique customer.
-
It contains the target column storing the outcomes (True/False values to denote whether each customer will have transactions exceeding a total of $5000 in the following month) and the input columns such as age, gender, the average spend on different days of the week, average spend on different types of items, frequency of spend, etc for each customer.
Feature columns should be interpretable in an ML-ready dataset
On the Engine, features in an ML-ready dataset don't need to be vectorized, imputed or scaled. You don't need to:
-
Impute (with mean, median, zero, etc.)
-
Scale (normalization)
-
One-hot encode or ordinal encode categorical columns
-
Normalize, tokenize, lemmatize or vectorize text columns
These steps will be handled automatically by the Engine before passing it on to the ML algorithm, using an appropriate ML pipeline, and the same will be repeated during prediction time as well. Hence, you don't need to manually perform them.
In fact, it is strongly recommended to leave feature columns “as is” in an ML-ready dataset regardless of their types (categorical, numeric, or text) so that the analysis produced by the Engine's explainable AI features are easily understandable and consumable in reports.
The Engine provides the tools necessary to generate an ML-ready dataset
The Engine’s end-to-end tool chain includes the “data wrangling recipe” function which can be used to clean, prepare, aggregate, and reshape the data to generate the features and target column in an ML-ready dataset. What features to generate for a given business problem depends on domain knowledge and is at the user’s discretion.
Templates automate the process of generating an ML-ready dataset
Templates make the process easier on the Engine, by automating the generation of an ML-ready dataset. By using templates tailored to particular business use cases (such as customer churn), the user only needs to provide their raw datasets and answer a few questions. The Engine takes care of everything else, including the generation of an ML-ready dataset.