December 2023 marked the release of 1.12.1: Enhanced data connections, a revamped Customer churn template, and user-friendly model building.
In this release of the AI & Analytics Engine, we aim to resolve user journey issues arising from the introduction of major new features throughout 2023 as well as add new data connectors.
This release means you will now be able to work with the Engine even more efficiently and seamlessly.
The notable changes introduced in this release are:
-
Support for more import and export data connections to seamlessly integrate your favourite ecosystems with the Engine
-
A more logical and streamlined experience for the Customer churn template: You first specify the business requirements, and we advise the amount of data (in terms of time span) you need to import, to be able to build models without encountering errors
-
New option within the Build from scratch flow to specify features to excluded from model training
-
A new streamlined experience to train additional models within an app with different sets of features so you can experiment faster
Customer churn template
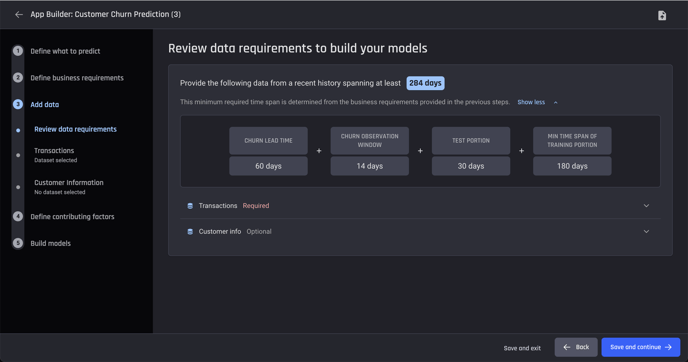
When we deployed the initial version of the Customer Churn template, we realised that many users did not have a sufficient time span of data, so encountered validation errors after the data was fully imported and analysed, which took a few minutes. Even though the validation error advises the minimum required time span of data, we thought it would be better if we advised users in advance how many days of data they require, before they add datasets into the template.
So we made the following changes.
In the very first step, we now ask for your business requirements: your desired prediction lead time, your definition of churn, and your desired prediction frequency. Based on that prediction frequency, we advise that a certain number of days of data will be reserved for testing models.
In the next step, Review data requirements the Engine advises how many days of historical data you need to supply for training and testing, to be able to satisfy your business requirements.
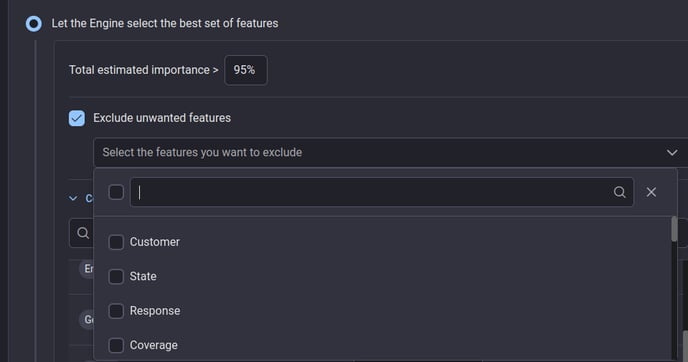
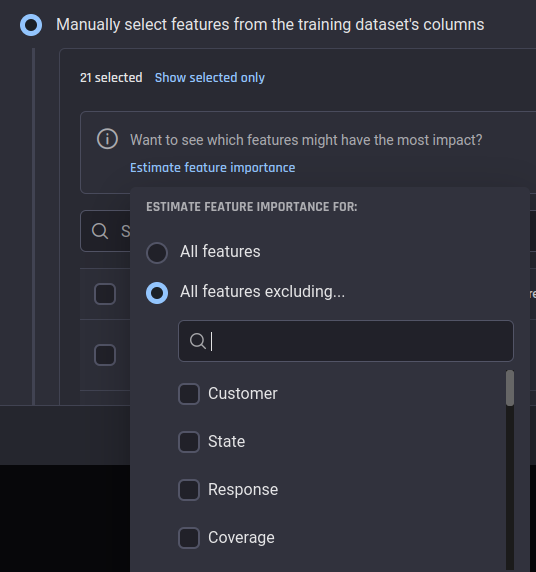
Build from scratch: Exclusion of irrelevant features from your model
In this release, we have introduced additional options in Step 3 of the App builder to exclude some features from consideration:
-
While letting the Engine select the best set of features (option 1)
-
While estimating feature importances to guide manual selection of features (option 2)
This allows you to exclude the unwanted features such as the following from consideration:
-
Irrelevant features that slow down analysis, training, and prediction
-
Target leakage columns created during exploratory phase
Training new models within an app
We have also introduced a smooth user experience by offering a new Train new model function within the app. In the new Train new model dialog, you can:
-
Re-use a previous feature selection or manually select a new set of features and feature types. To aid manual selection, you can estimate feature importance scores of candidate features, as in the app builder.
-
Specify requirements in terms of prediction quality and training time in selecting models.
-
If you are re-using a previously analyzed set of features, you will immediately see the model recommender’s output showing the algorithms that satisfy this criterion, along with the estimated training times and prediction quality.
-
If you are using new feature selection that has not been previously analyzed, you can either let the Engine select the best set of features or manually specify the algorithms to train, just as in the app builder.
-
We have also introduced the concept of “training requests” to have an update about the background task that processes the selected features followed by training the requested models.
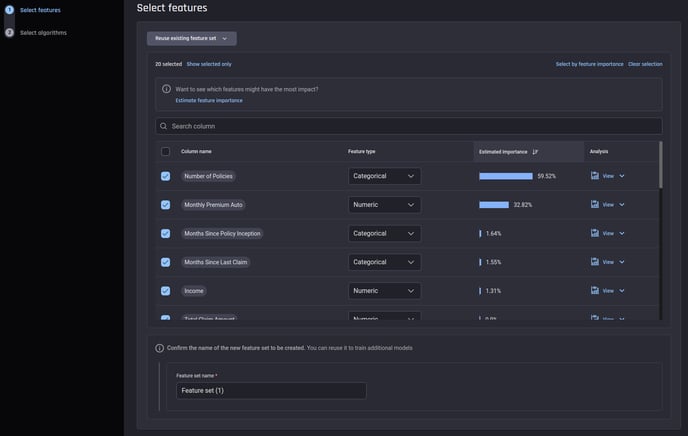 Train new model step 1: Select features
Train new model step 1: Select features
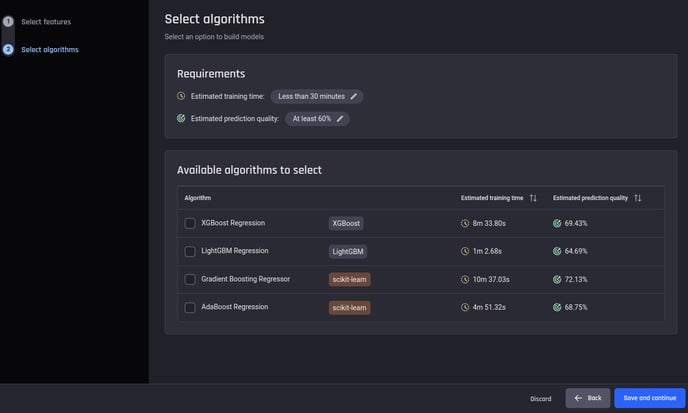 Train new model step 2: Select algorithms (feature set analyzed previously)
Train new model step 2: Select algorithms (feature set analyzed previously)
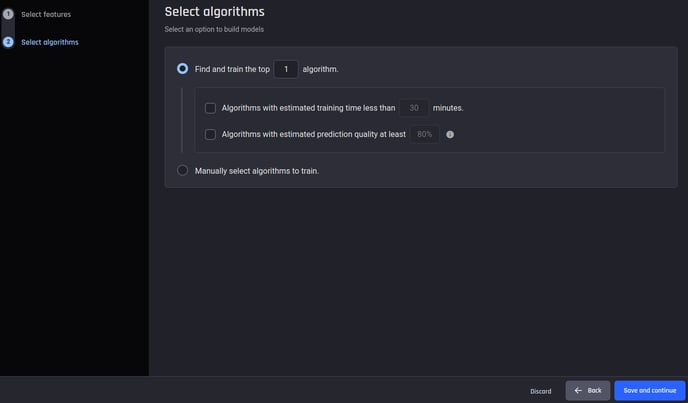 Train new model step 2: Select algorithms (feature set not analyzed previously)
Train new model step 2: Select algorithms (feature set not analyzed previously)
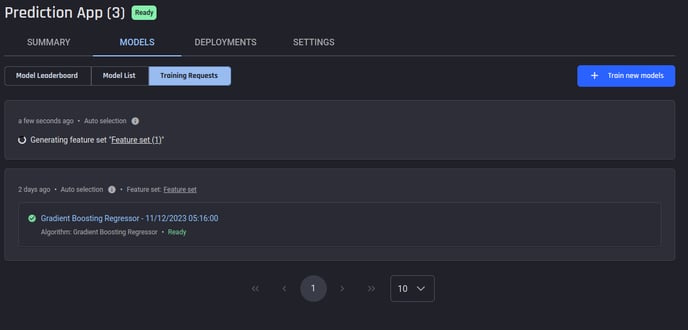
Training requests listing
Connectors
Wishing to give you a seamless experience between the Engine and your current software ecosystem, direct connections to a variety of apps and databases have been implemented to easily and quickly import and export data.
Newly added import options include are Google Sheets, AWS Redshift and Google BigQuery. For export, newly added options are AWS RDS, AWS Redshift, Google Cloud SQL, and Google BigQuery.
.png?width=688&height=558&name=image-20231129-102715%20(1).png)