Release 1.12.0 saw two new enhancements to the AI and Analytics Engine new data import connectors and a new app builder flow for developing your clustering pipeline.
In this November release, we are pleased to introduce two exciting enhancements to the AI & Analytics Engine’s capabilities:
-
New data connectors for import: You now have more ways to import datasets into the Engine for analytics and machine learning. Our future releases will see the introduction of more data connectors for both import and export, in phases. You will be able to seamlessly connect to your datasets from a wide variety of sources. New connectors introduced in this release include: cloud storage solutions, additional database connections, and Stripe.
-
New app builder for clustering: Using the “build from scratch” option, you can now prepare your dataset and apply clustering over it in a single flow. The outputs - clustered dataset and the insights - will be available at the end as usual. We also have a better UI for selecting and inspecting features. Clustering now comes under the “seamless ML pipeline builder” approach that we introduced a few months ago for regression and classification.
New data connectors for importing datasets
This release brings you many new data connectors for conveniently importing your datasets into the Engine. Additionally, you now have a way to filter the input connectors by category.
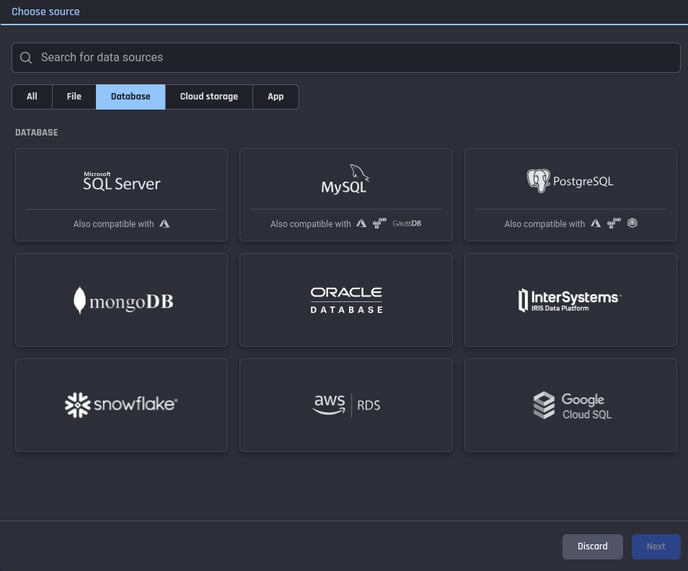
Data Import
Cloud storage
You can now import files from any of the following cloud storage providers:
-
AWS S3
-
Google Cloud Storage
-
Microsoft Azure Blob Storage
Supported file formats and rules regarding the import of multiple files at once into a single dataset remain the same as the “Local File Upload” option:
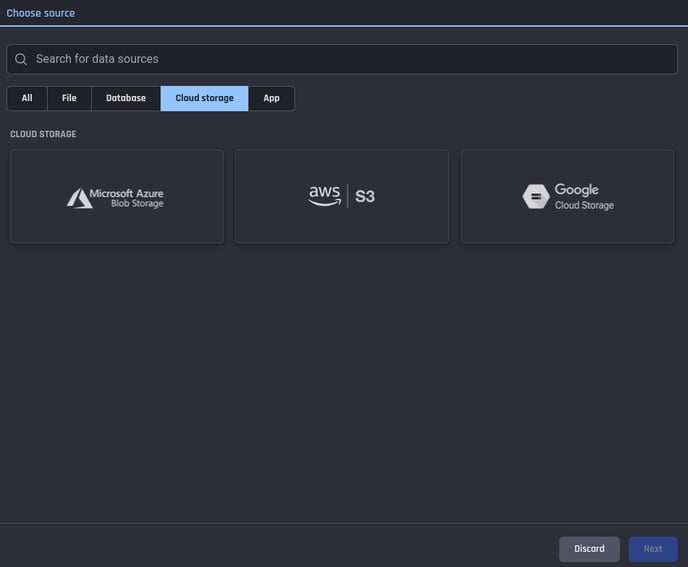 Data import, cloud storage
Data import, cloud storage
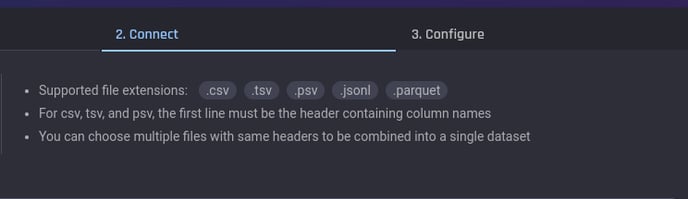 Data import, cloud storage rules
Data import, cloud storage rules
Database
We have added support for new database connections:
-
AWS RDS
-
Google Cloud SQL
Our existing database connections (MySQL, PostgreSQL, etc.) continue to work as before. Note that these existing connectors are compatible with various providers such as Microsoft Azure SQL, Amazon Aurora, GaussDB and Google Alloy.
App
In this release, we have added support to import data from Stripe. We will expand to support additional third-party apps in future releases.
Within stripe, you can import the chosen dataset objects:
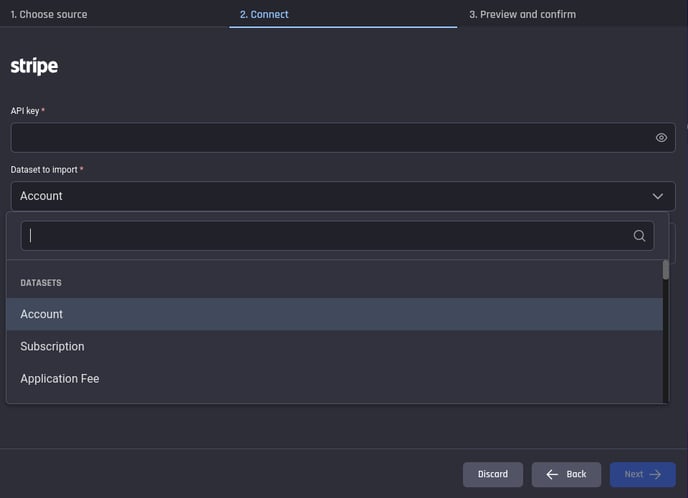
Stripe, connect screen
New app builder for clustering
In the new app builder for clustering, you can add and prepare datasets before proceeding to run clustering algorithms:
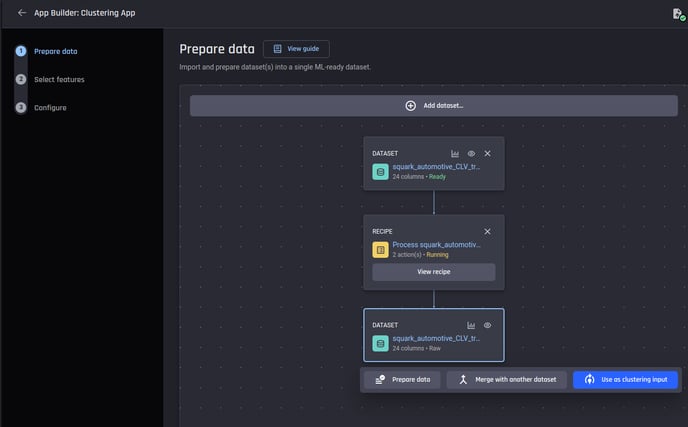 Clustering app builder pipeline
Clustering app builder pipeline
You can now specify feature types while selecting features.
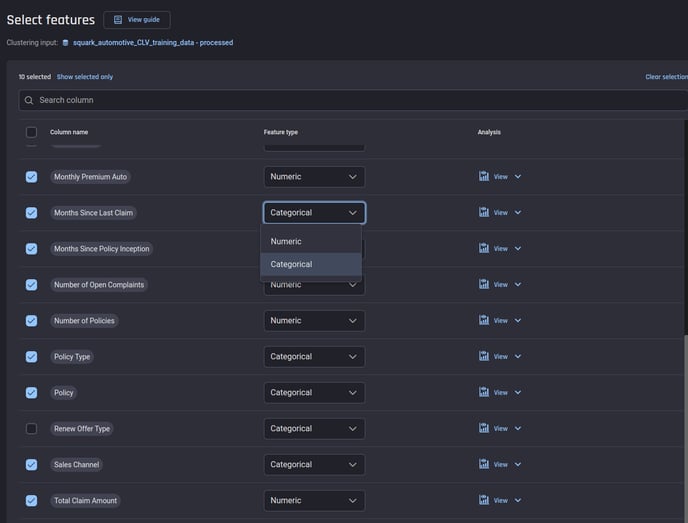 Feature selection, clustering app builder
Feature selection, clustering app builder
You can also see summary stats and a visualization of your column that are apt to your choice of feature type.
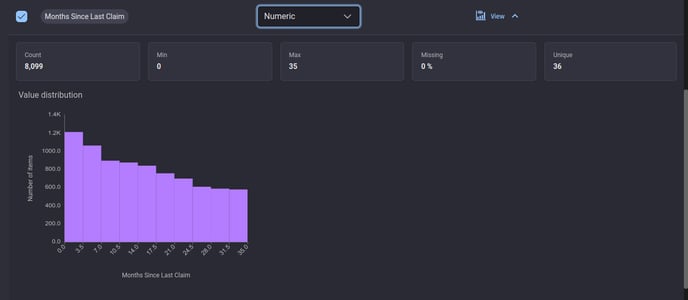 Feature selection, details view
Feature selection, details view
The app setup page for clustering follows a similar layout as regression/classification apps, and you can access individual clustering results from there via "View details".
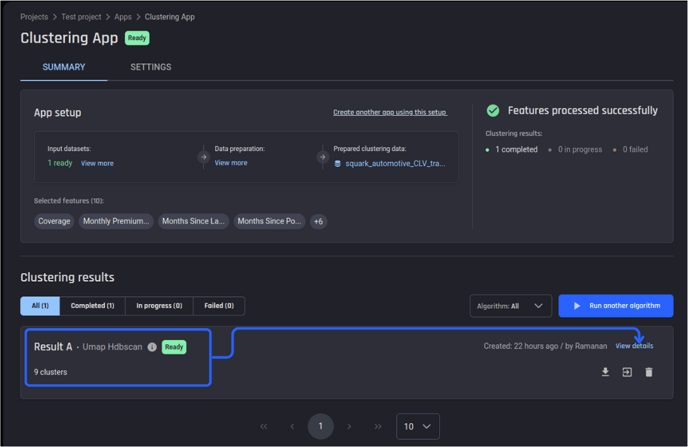 Clustering app summary
Clustering app summary
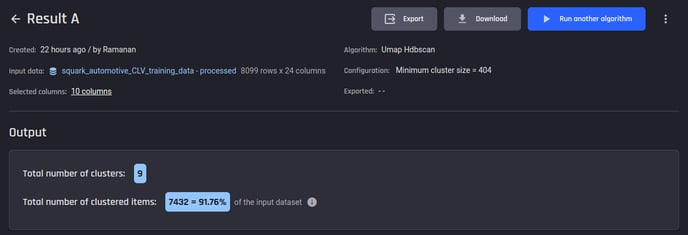 Clustering results
Clustering results
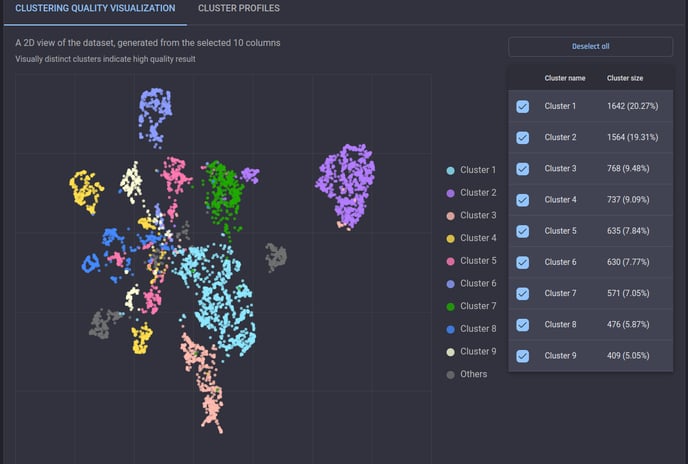 Clustering quality visualized
Clustering quality visualized
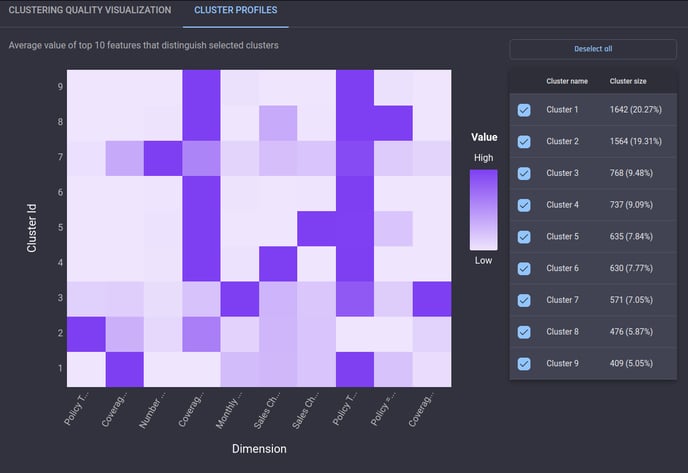 Cluster profiles
Cluster profiles
🎓If you want to try out the new clustering pipeline read how to build a clustering pipeline to get started.