This article explains how the top algorithms are automatically selected in the customer churn prediction template.
Once contributing factors are confirmed in the customer churn template, we can proceed with model training. Before training a model, we need to select an algorithm. There are various algorithms supported in the Engine for classification. The question here lies in which algorithm(s) should we try.
While it may seem logical to train all available algorithms before selecting one based on evaluation results on the test set, the time required to wait for a large number of models to complete training and evaluation can be substantial, especially when computational resources are limited. Furthermore, even in the absence of such limitations, the cost of computation can be unexpectedly high, and might exceed the allocated budget.
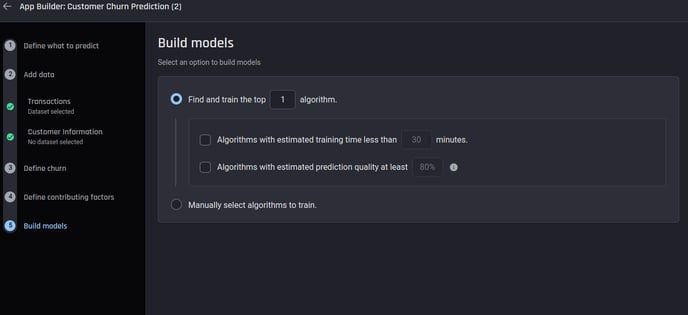
To address the aforementioned issues, the Engine estimates the performance of the resulting trained model from each algorithm, before any training actually happens (read this article on model recommender for more information). The user can confirm the number of algorithms to be trained, and only the specified number of algorithms with top estimated performance will be trained.
The user can optionally specify additional constraints on the prediction quality and the training time. Only algorithms whose estimated performances fall within these constraints will be considered while determining the top ones.