.png?width=1080&height=600&name=infographic%20diagram%20decision%20tree%20(1).png) Regression vs Classification
Regression vs Classification.png?width=1080&height=600&name=infographic%20diagram%20decision%20tree%20(2).png)
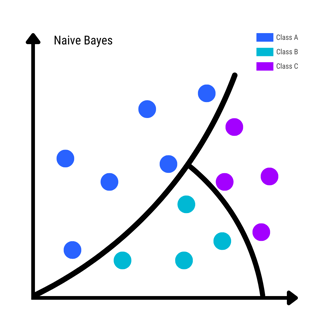
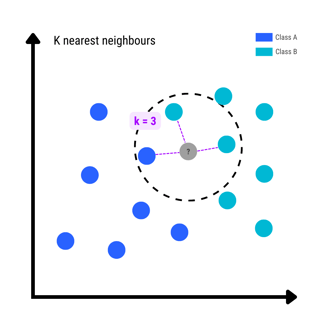
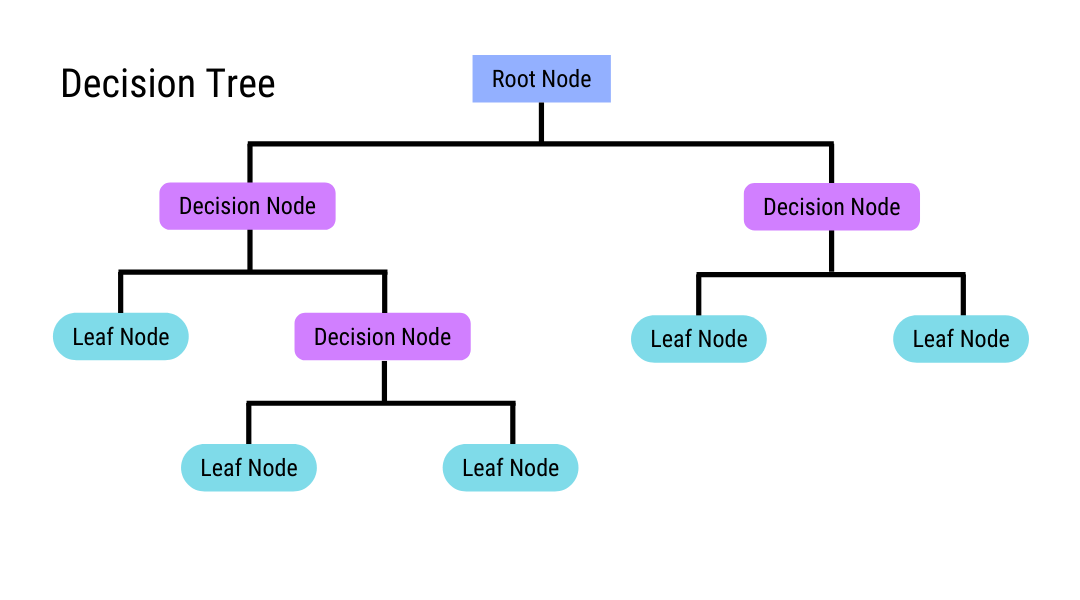
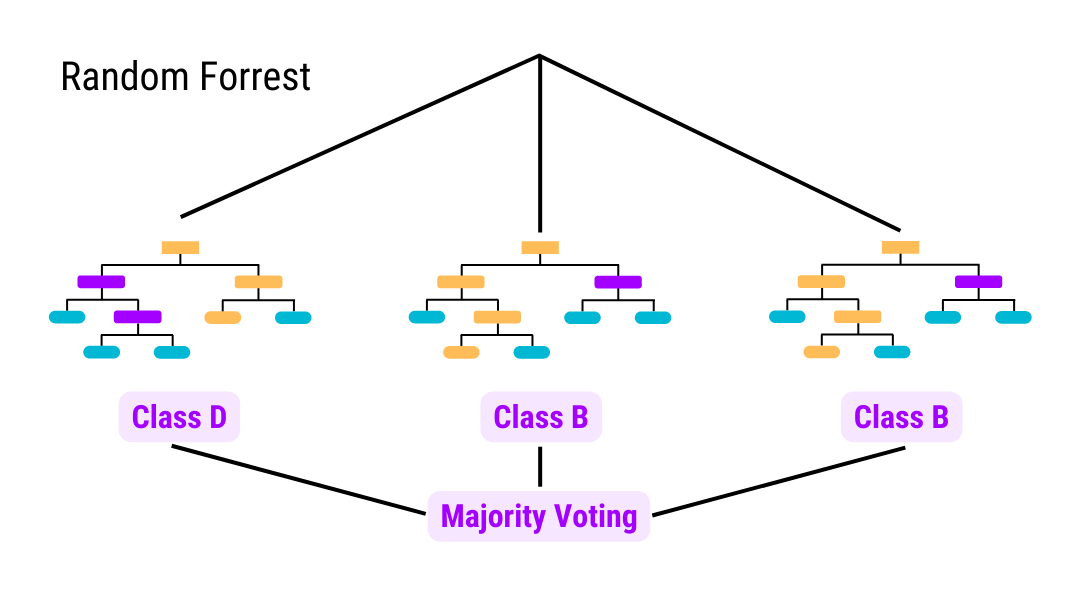


Classification
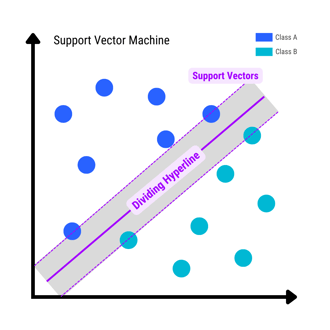
Support Vector Classifier Simply Explained [With Code]
Let's take a deep dive & try to understand Support Vector Classifier, a popular supervised machine learning classification algorithm with the help of...