-png.png)

-png.png)
-png.png)
-png.png)
-png.png)
-png.png)
-png.png)
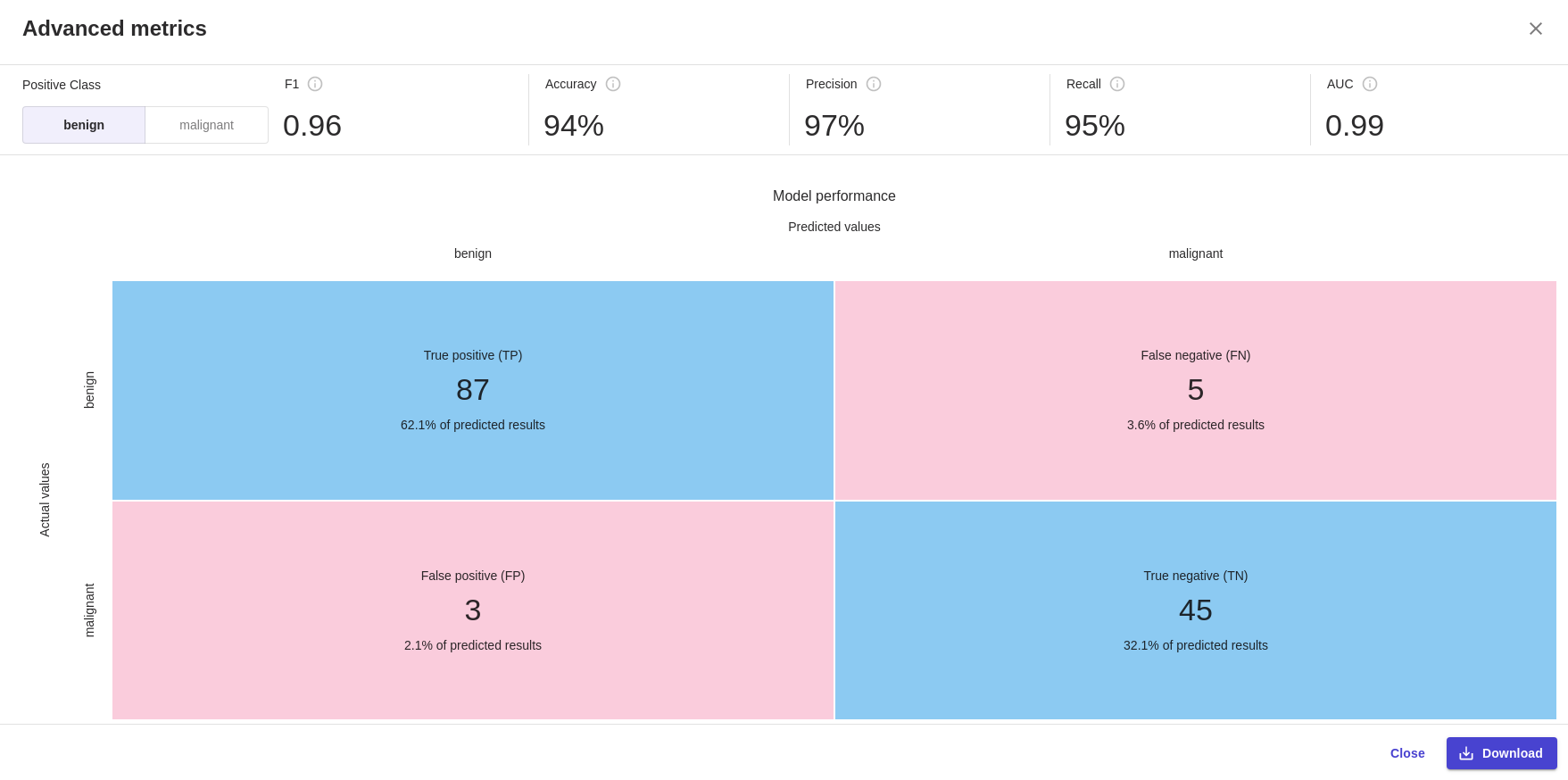
-png.png)
-png.png)
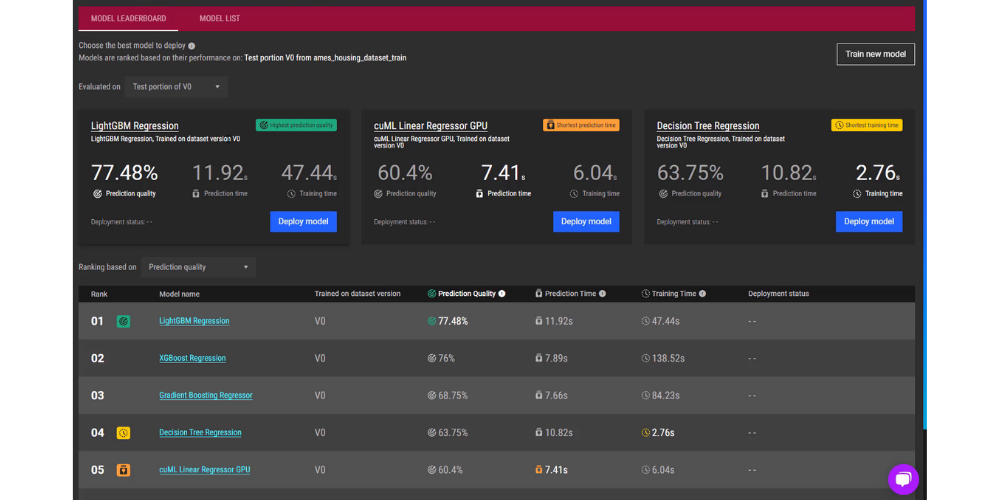
-png.png)
-png.png)
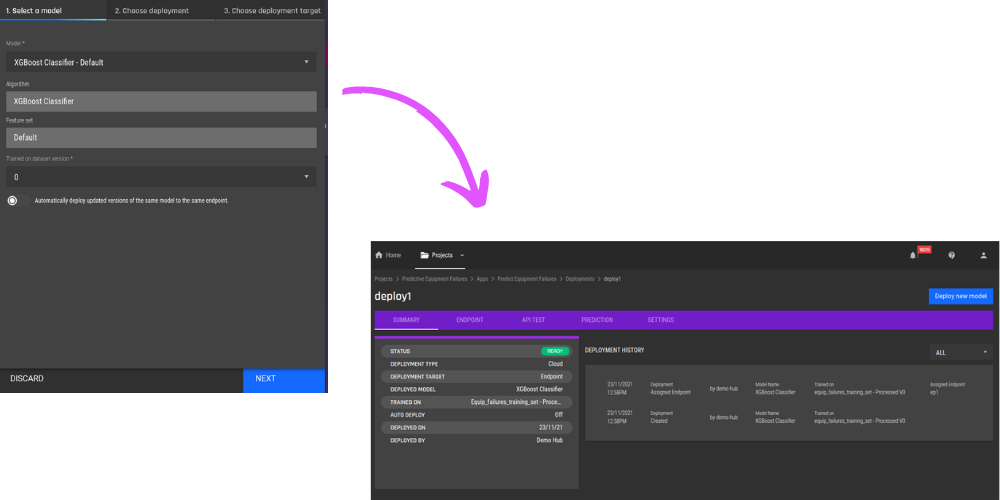
-png.png)
-png.png)
-png.png)

Integrations
How to use the AI & Analytics Engine’s Google Sheets Integration
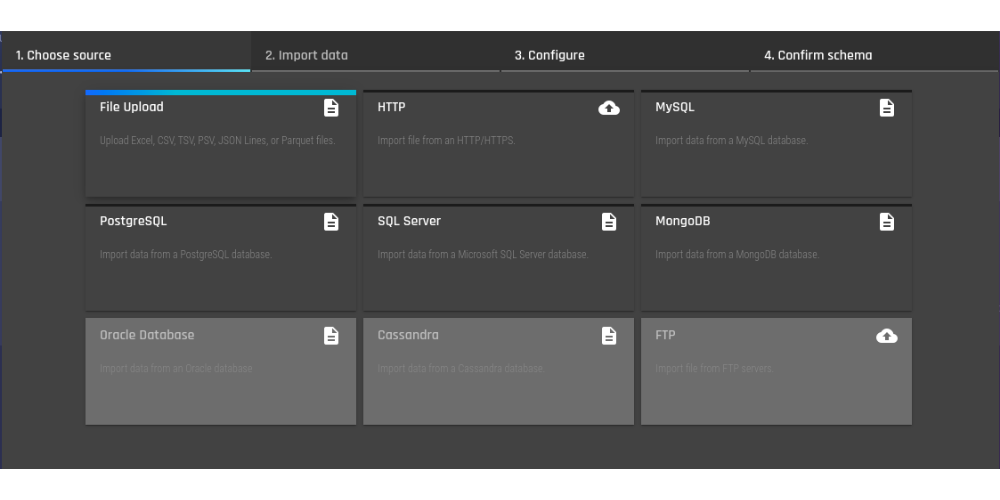
In this blog, we’ll show how to import data using the AI & Analytics Engine’s Google Sheets integration, so you can build machine learning models.