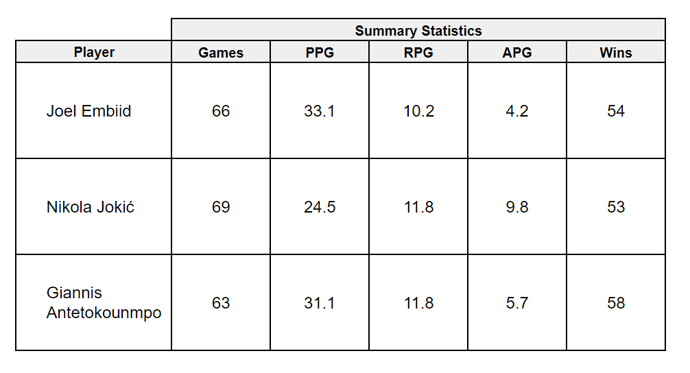
 The contenders' summary stats
The contenders' summary stats.png?width=680&height=262&name=image%20(13).png) The Dataset
The Dataset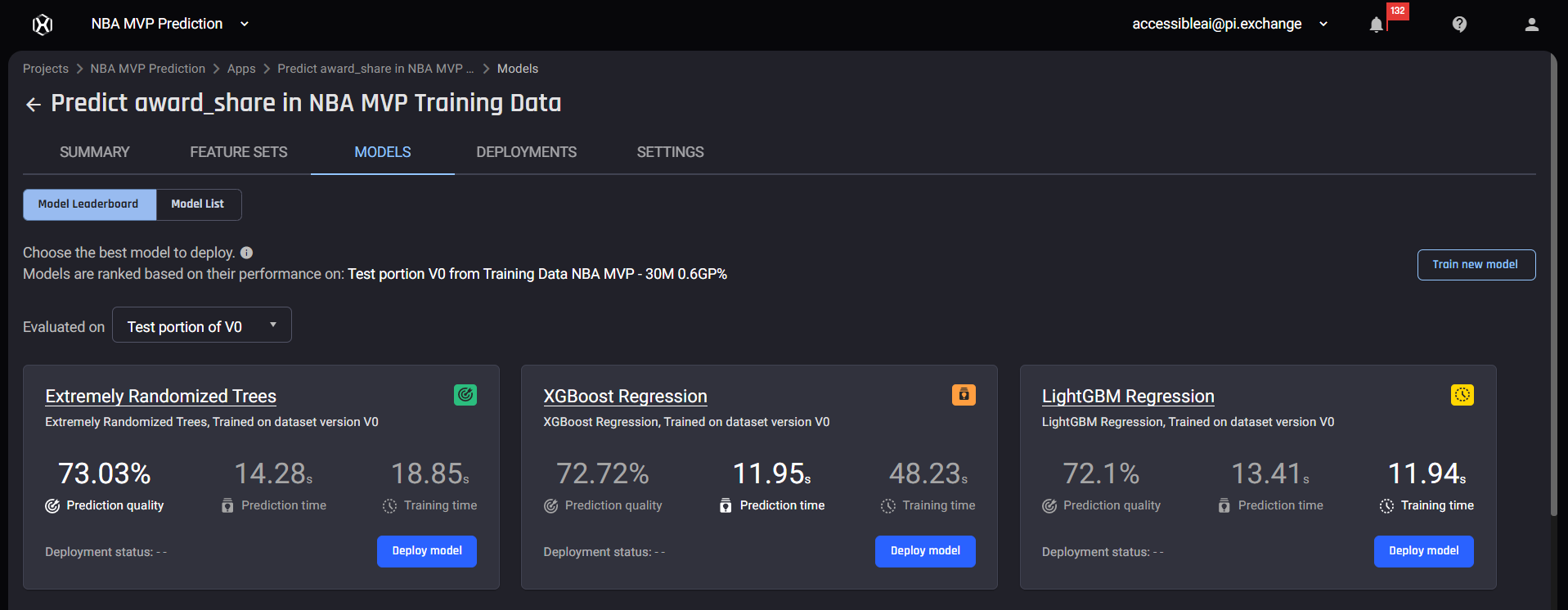 Model Summary in the AI&A Engine
Model Summary in the AI&A Engine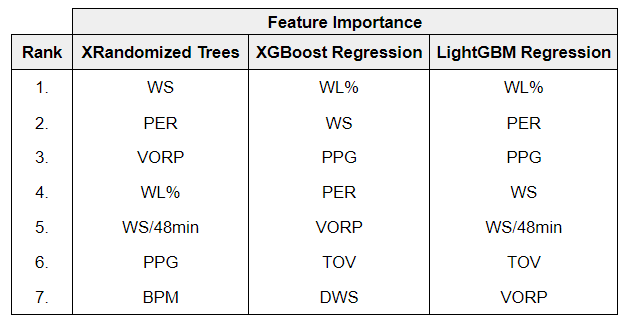 Feature importance of the ML models
Feature importance of the ML models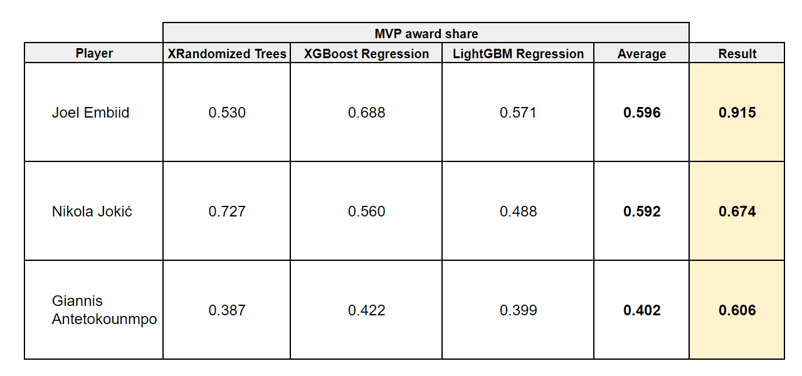

Classification
Titanic Survival Prediction using No-Code Machine Learning
We’ll be using the no-code AutoML platform, the AI & Analytics Engine, to build machine learning models to predict survivors on the Titanic.