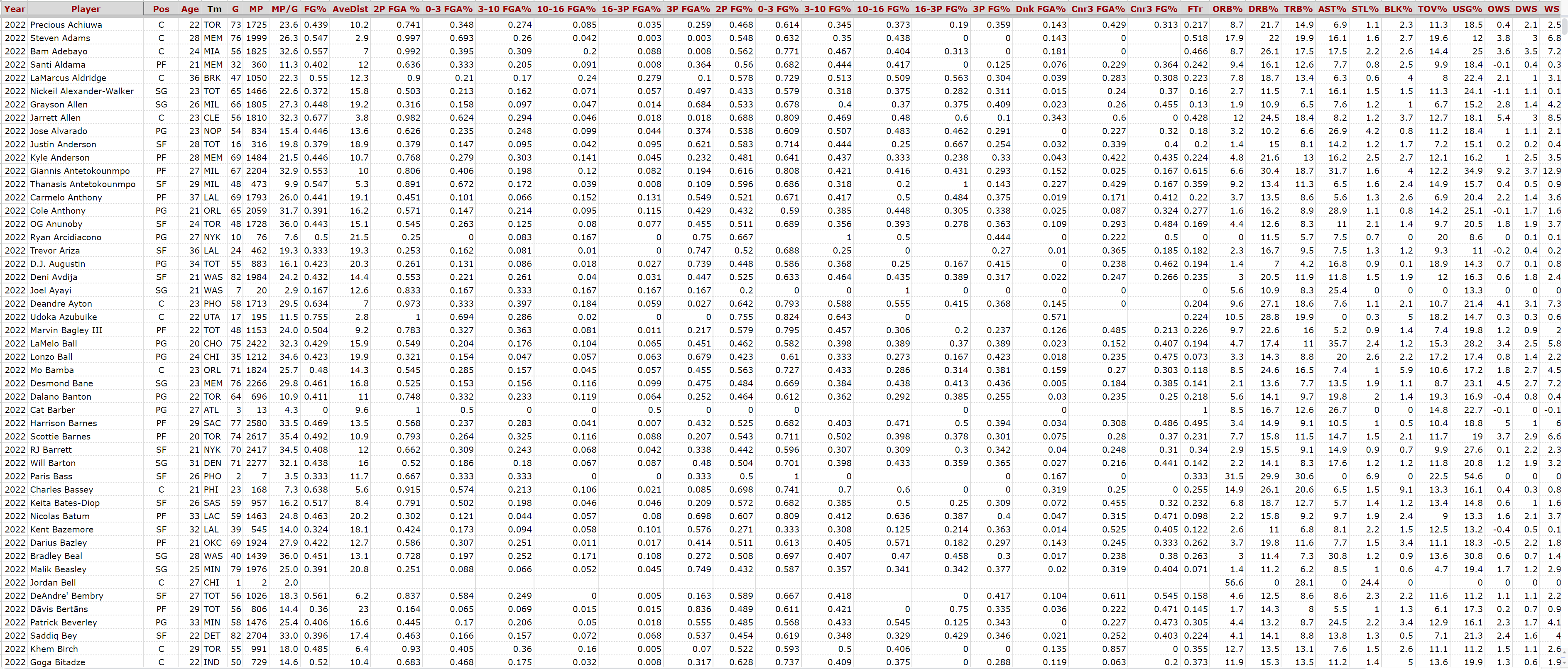
 The dataset
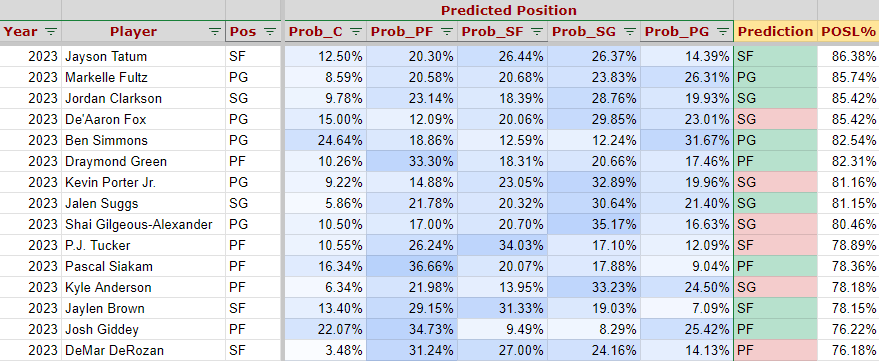
The dataset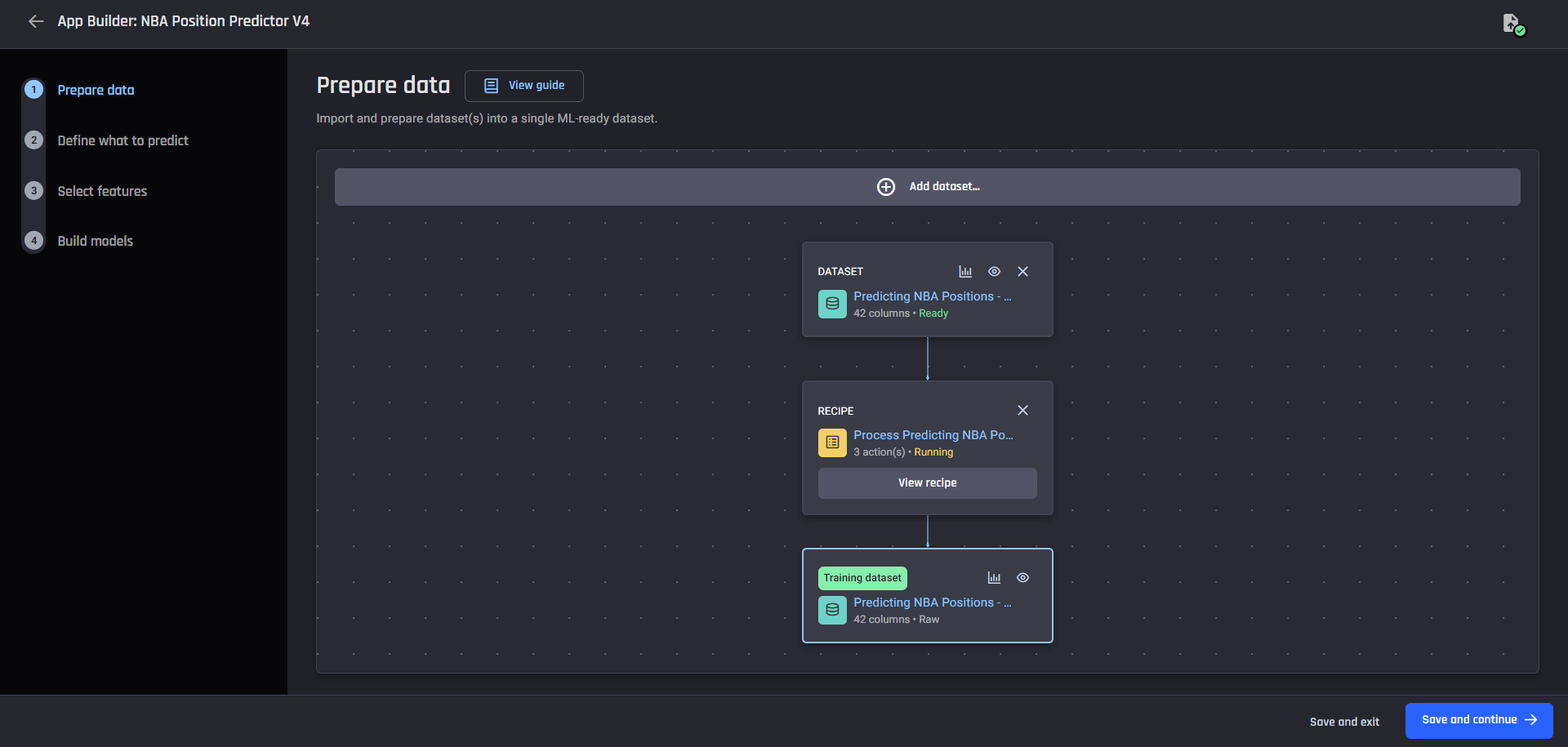 Data preparation pipeline with recipe
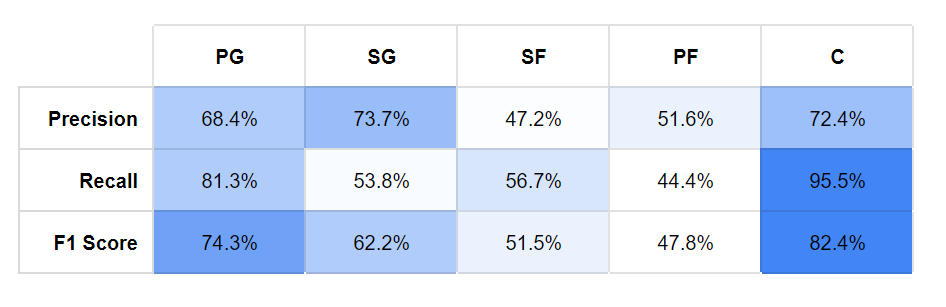
Data preparation pipeline with recipe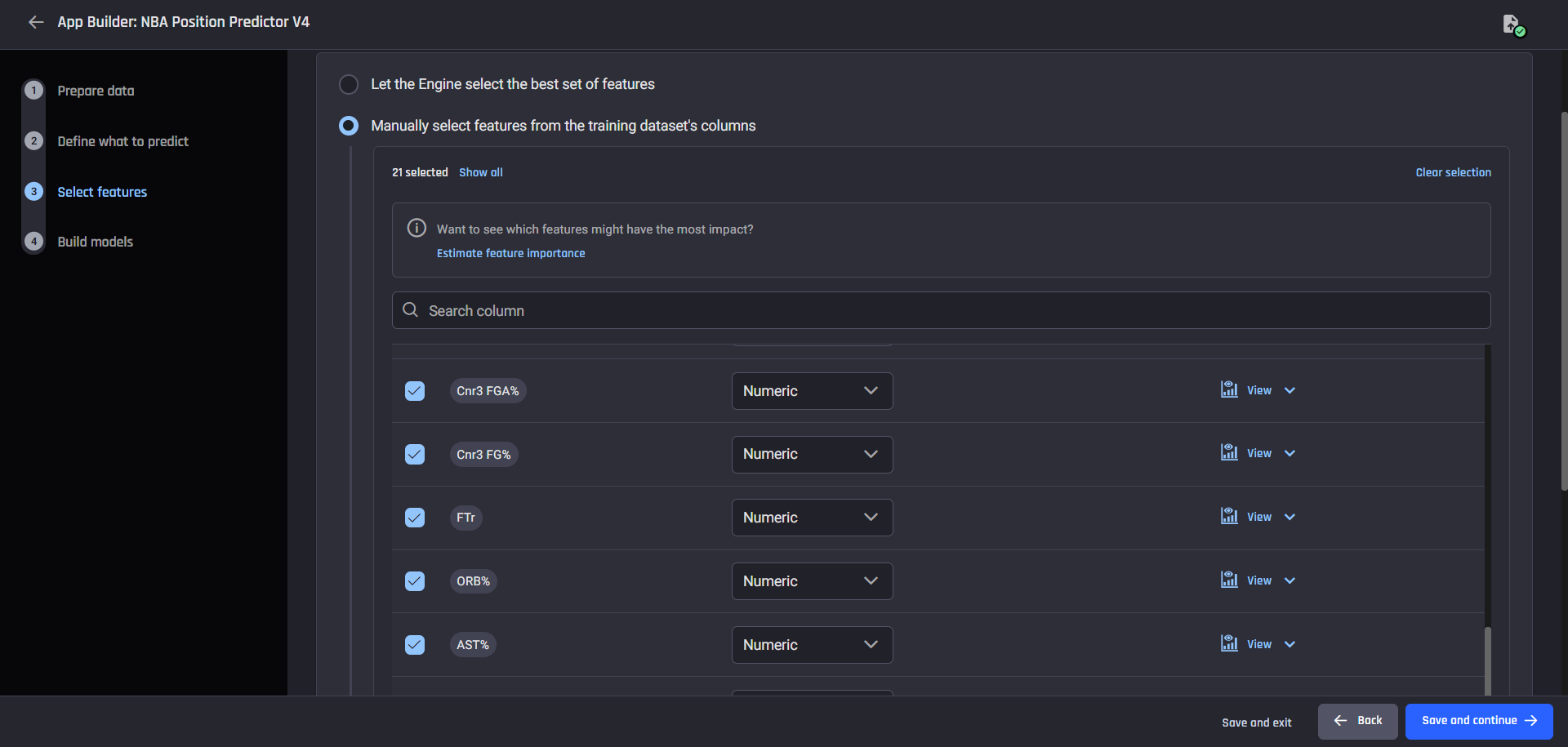 Feature selection
Feature selection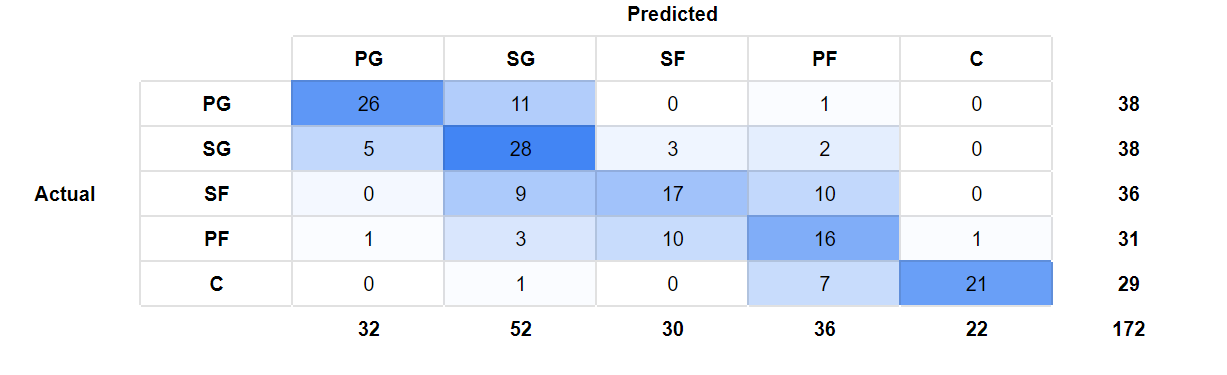
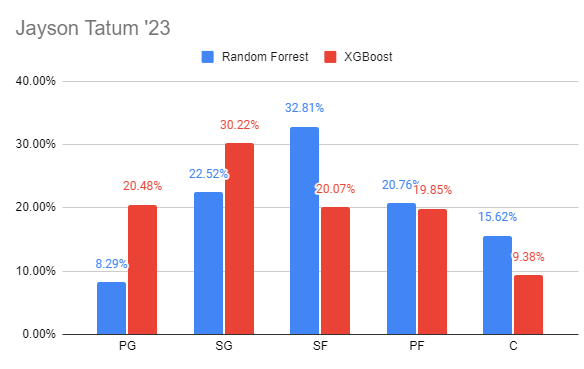 Jayson Tatum's position predictions for both models
Jayson Tatum's position predictions for both models Prediction explanation for Jayson Tatums SF prediction by the Random Forest model
Prediction explanation for Jayson Tatums SF prediction by the Random Forest model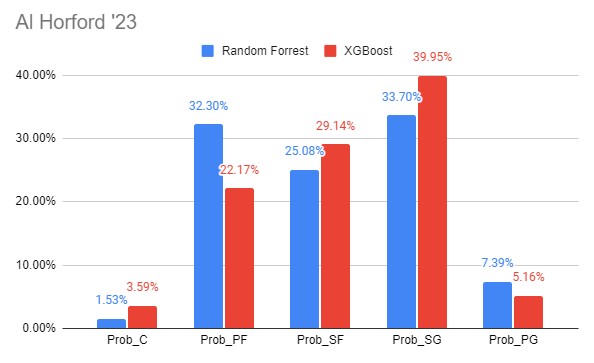 Al Horford's position predictions for both models
Al Horford's position predictions for both models
Predictive analytics
How Predictive Analytics is Driving Evolution in Insurance
The adoption of predictive analytics in the insurance industry is spearheading rapid evolution, leading to improved efficiency, and streamlined...