
.png?width=800&name=Blog%20Images%20(46).png)



-png-1.png?width=800&name=Blog%20Images%20(47)-png-1.png)
.png?width=800&name=Blog%20Images%20(48).png)

.png?width=800&name=Blog%20Images%20(49).png)
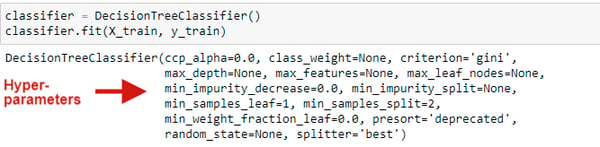
.png?width=800&name=Blog%20Images%20(50).png)

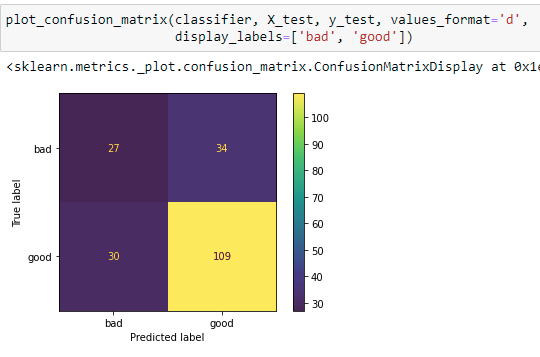
.png?width=800&name=Blog%20Images%20(51).png)
.png?width=800&name=Blog%20Images%20(52).png)

.png?width=800&name=Blog%20Images%20(53).png)
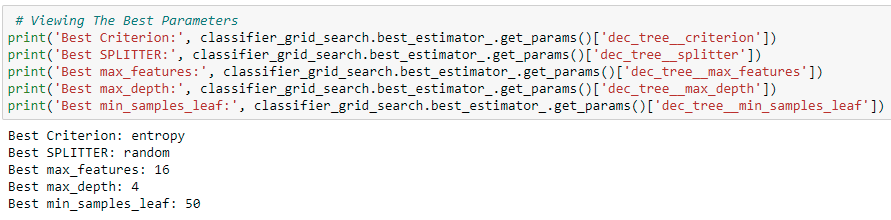

.png?width=800&name=Blog%20Images%20(55).png)
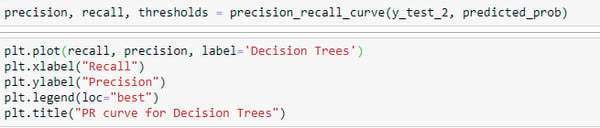
.png?width=1000&name=Blog%20Images%20(56).png)

.png?width=800&name=Blog%20Images%20(57).png)
.png?width=800&name=Blog%20Images%20(58).png)
-1.png?width=800&name=Blog%20Images%20(59)-1.png)
.png?width=800&name=Blog%20Images%20(60).png)
.png?width=800&name=Blog%20Images%20(61).png)
.png?width=800&name=Blog%20Images%20(63).png)
.png?width=800&name=Blog%20Images%20(64).png)
.png?width=800&name=Blog%20Images%20(65).png)
.png?width=800&name=Blog%20Images%20(67).png)
.png?width=800&name=Blog%20Images%20(68).png)
.png?width=800&name=Blog%20Images%20(69).png)
.png?width=800&name=Blog%20Images%20(70).png)
.png?width=800&name=Blog%20Images%20(71).png)
.png?width=800&name=Blog%20Images%20(72).png)
.png?width=800&name=Blog%20Images%20(73).png)
.png?width=800&name=Blog%20Images%20(74).png)
.png?width=800&name=Blog%20Images%20(75).png)
.png?width=800&name=Blog%20Images%20(76).png)
.png?width=800&name=Blog%20Images%20(77).png)
.png?width=800&name=Blog%20Images%20(78).png)
.png?width=800&name=Blog%20Images%20(79).png)
.png?width=1000&name=Blog%20Images%20(80).png)
.png?width=800&name=Blog%20Images%20(81).png)
.png?width=800&name=Blog%20Images%20(82).png)

ML for small businesses
The Rise of GPUs in the AI Universe
GPUs are empowering data scientists and machine learning engineers to train their models in minutes which could potentially take days or weeks.